[学习笔记]机器学习相关概念
一、欠拟合与过拟合
1、定义
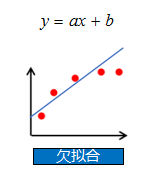
欠拟合:模型在训练集上误差很高
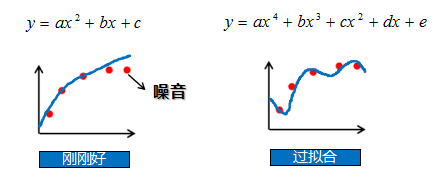
过拟合:在训练集上误差低,测试集上误差高
2、原因
欠拟合:模型过于简单,没有很好的捕捉到数据特征,不能很好的拟合数据
过拟合:模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,模型泛化能力太差
3、图例
二、偏差与方差
1、定义
偏差:预计值的期望与真实值之间的差距
方差:预测值的离散程度,也就是离其期望值的距离
2、图例

上图表示,如果一个模型在训练集上正确率为 80%,测试集上正确率为 79% ,则模型欠拟合,其中 20% 的误差来自于偏差,1% 的误差来自于方差。如果一个模型在训练集上正确率为 99%,测试集上正确率为 80% ,则模型过拟合,其中 1% 的误差来自于偏差,19% 的误差来自于方差。可以看出,欠拟合是一种高偏差的情况。过拟合是一种低偏差,高方差的情况。
三、衡量回归的性能指标
1、MSE (Mean Squared Error)均方误差
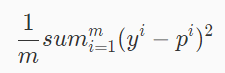
其中y的i次方表示第 i 个样本的真实标签,p的i次方表表示模型对第 i 个样本的预测标签。线性回归的目的就是让损失函数最小。那么模型训练出来了,我们在测试集上用损失函数来评估模型就行了。
2、RMSE(Root Mean Squard Error)均方根误差
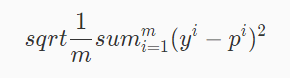
RMSE 其实就是 MSE 开个根号。有什么意义呢?其实实质是一样的。只不过用于数据更好的描述
3、MAE (平均绝对误差)
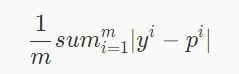
MAE 虽然不作为损失函数,确是一个非常直观的评估指标,它表示每个样本的预测标签值与真实标签值的 L1 距离
4、R-Squared
上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价 那么误差单位就是万元。数子可能是 3,4 ,5 之类的。那么预测身高就可能是 0.1,0.6 之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。 看看分类算法的衡量标准就是正确率,而正确率又在 0~1 之间,最高百分之百。最低 0 。如果是负数,则考虑非线性相关。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢? R-Squared 就是这么一个指标,公式如下:
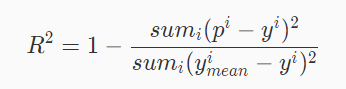
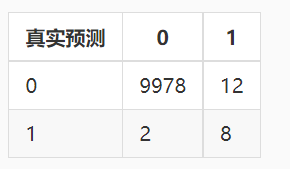
四、混淆矩阵
以癌症检测系统为例,癌症检测系统的输出不是有癌症就是健康,这里为了方便,就用 1 表示患有癌症,0 表示健康。假设现在拿 10000 条数据来进行测试,其中有 9978 条数据的真实类别是 0,系统预测的类别也是 0,有 2 条数据的真实类别是 1 却预测成了 0,有 12 条数据的真实类别是 0 但预测成了 1,有 8 条数据的真实类别是 1,预测结果也是 1,如果我们把这些结果组成如下矩阵,则该矩阵就成为混淆矩阵
混淆矩阵中每个格子所代表的的意义也很明显,意义如下:
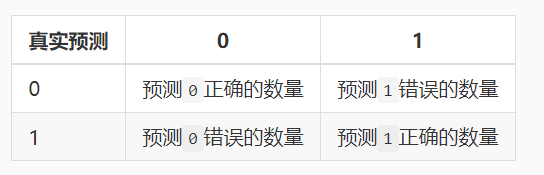
如果将正确看成是 True,错误看成是 False, 0 看成是 Negtive, 1 看成是 Positive。然后将上表中的文字替换掉,混淆矩阵如下:
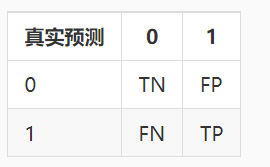
五、精准率与召回率
1、精准率
**精准率(Precision)**指的是模型预测为 Positive 时的预测准确度,其计算公式如下:
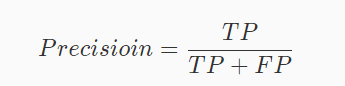
2、召回率
**召回率(Recall)**指的是我们关注的事件发生了,并且模型预测正确了的比值,其计算公式如下:
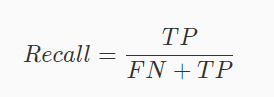
六、F1 Score
如果想要同时兼顾精准率和召回率,这个时候就可以使用 F1 Score 来作为性能度量指标。F1 Score 是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。 F1 Score 可以看作是模型准确率和召回率的一种加权平均,它的最大值是 1,最小值是 0。其公式如下:
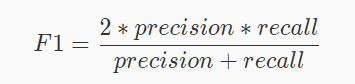
- 标题: [学习笔记]机器学习相关概念
- 作者: Thou
- 创建于 : 2022-02-01 21:15:52
- 更新于 : 2025-12-02 18:05:18
- 链接: https://blog.txgde.space/2022/02/01/学习笔记机器学习01/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。